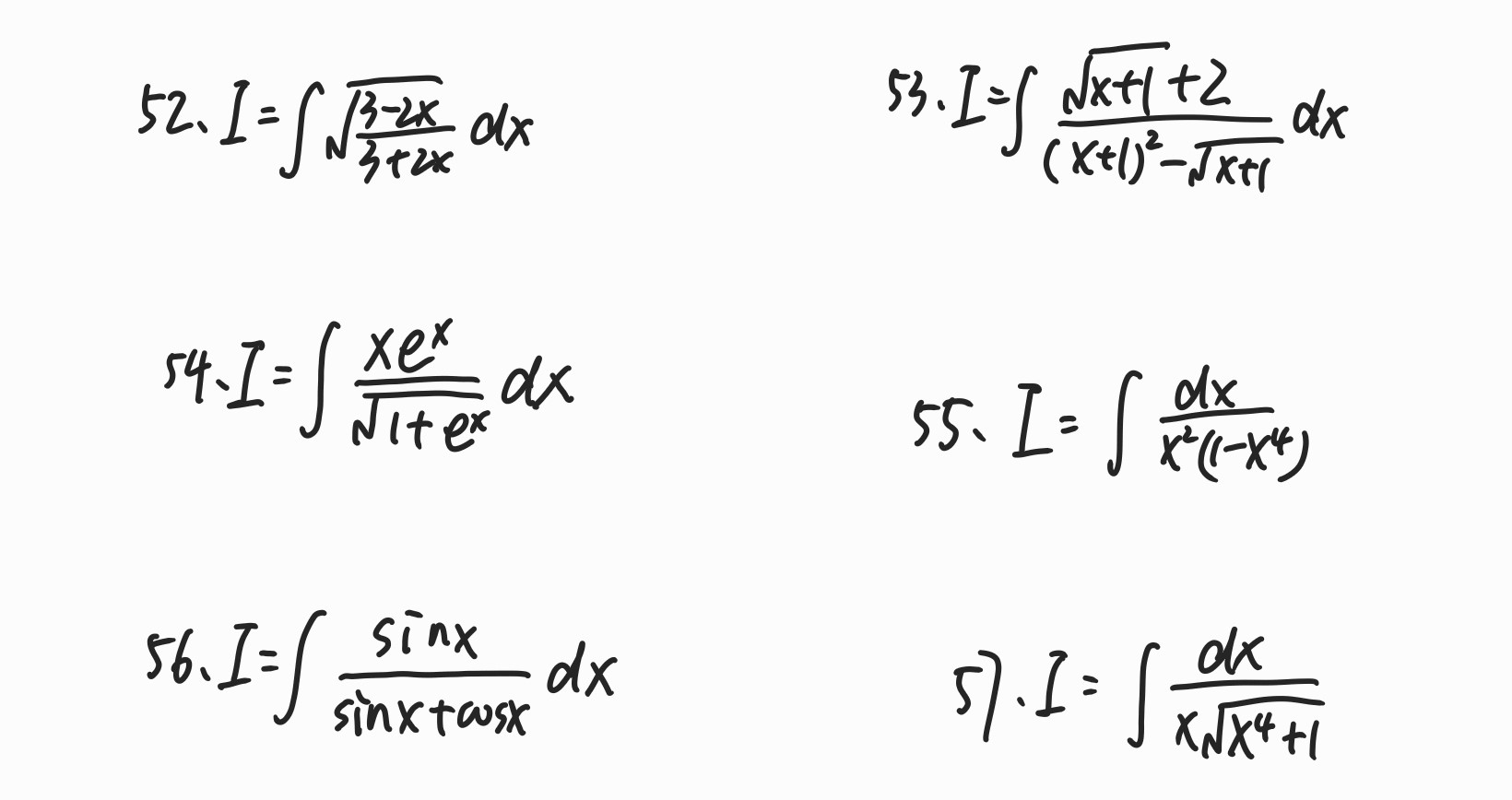Table of Contents
回顾
恋词复习


数据结构-线索二叉树-树(五)
线索二叉树原理
1个有n个结点的二叉链表。每一个结点有指向左右孩子的两个指针域,一共是2n个指针域。n个结点的二叉树一共同拥有n-1条分支线(根结点无前驱),存在2n-(n-1)=n+1个空指针域

将指向前驱和后驱的指针称为线索,加上线索的二叉链表则称为线索链表;加上线索的二叉树称为线索二叉树(Threaded Binary Tree)
中序遍历后,将所有的空指针域中的rchild,改为指向它的后继结点。通过指针知道H的后继是D(①),I的后继是B(②),J的后继是E(③),E的后继是A(④),F的后继是C(⑤),G的后继因为不存在而指向NULL(⑥)。此时共有6个空指针域被利用

将这棵二叉树的所有空指针域中的lchild,改为指向当前结点的前驱。H的前驱是NULL(①),I的前驱是D(②),J的前驱是B(③),F的前驱是A(④),G的前驱是C(⑤)。一共5个空指针域被利用,正好和上面的后继加起来是11个

线索二叉树,等于是把一棵二叉树转变成了一个双向链表,对插入删除结点、查找某个结点都带来了方便。
对二叉树以某种次序遍历使其变为线索二叉树的过程称做是线索化

空心箭头实线为前驱,虚线黑箭头为后继
每个结点再增设两个标志域ltag和rtag,ltag和rtag只是存放0或1数字的布尔型变量,占用的内存空间要小于像lchild和rchild的指针变量

- ltag为0时指向该结点的左孩子,为1时指向该结点的前驱
- rtag为0时指向该结点的右孩子,为1时指向该结点的后继

线索二叉树结构实现
二叉树的线索存储结构定义代码如下:
typedef eum {Link,Thread} PointerTag; /*二叉树的二叉线索存储结构定义*/
/*Link==0表示指向左右孩子指针*/
/*Thread==1表示指向前驱或后驱的线索*/
typedef struct BiThrNode /*二叉线索存储结点结构*/
{
TElemType data; //数据域:结点数据
struct BiThrNode *lchild,*rchild; //指针域:左右孩子指针
PointerTag LTag;
PointerTag RTag; //左右标志
}BiThrNode,*BiThrTree;
线索化的实质就是将二叉链表中的空指针改为指向前驱或后继的线索。因为前驱和后继的信息只有在遍历该二叉树时才干得到,所以线索化的过程就是在遍历的过程中修改空指针的过程
中序遍历线索化的递归函数代码例如以下:
BiThrTree pre; //全局变量。始终指向刚刚訪问过的结点
/*中序遍历进行中序线索化*/
void InThreading(BitThrTree p)
{
if(p)
{
InThreading(p->lchild); //递归左子树线索化
if(!p->lchild) //结点无左孩子
{
p->LTag=Thread; //前驱线索:将结点左指针标志置1,说明左指针指向该结点的前驱
p->lchild=pre; //左孩子指针指向前驱
}
if(!pre->rchild) //前驱没有右孩子
{
pre->RTag=Thread; //后继线索
pre-rchild=p; //前驱右孩子指针指向后继(当前结点p)
}
pre=p; //保持pre指向p的前驱
InThreading(p->rchild); //递归右子树线索化
}
}
源代码分析:
(1)结点前驱线索化
if(!p->lchild)表示假设某结点的左指针域为空,由于其前驱节点刚刚訪问过,赋值给了pre,所以能够将pre赋值给p->lchild。并改动p->LTag=Thread(也就是定义为1)以完成前驱结点的线索化。
(2)结点后驱线索化 因为该节点还没有訪问到,因此仅仅能对它的前驱结点pre的右指针rchild做推断,if(!pre->rchild)表示假设为空。则p就是pre的后继,于是pre->rchild=p,而且设置pre->RTag=Thread。完毕后继结点的线索化。
(3) pre=p语句的作用是完毕前驱和后继的推断后,将当前的结点p赋值给pre。以便下一次使用 二叉树的二叉线索存储表示(以中序为例):在线索链表上加入一个头结点,并令其lchild域的指针指向二叉树的根结点(图中的①)。其rchild域的指针指向中序遍历时訪问的最后一个结点(图中的②)。令二叉树中序序列中的第一个结点的lchild域指针和最后一个结点的rchild域的指针均指向头结点(图中的③和④。这样就创建了一个双向线索链表。优点是既能够从第一个结点起顺后继进行遍历。也能够从最后一个结点起顺前驱进行遍历

遍历的代码如下:
/*T指向头结点,头结点左链lchild指向根结点,头结点右链rchild指向中序遍历的最后一个结点*/
/* 中序遍历二叉线索链表表示的二叉树T,时间复杂度为O(n)*/
Status InOrderTraverse_Thr(BiThTree T)
{
BiThrTree p;
p=T->lchild; //p指向根结点
while(p != T) //空树或遍历结束时。p==T
{
while(p->LTag==Link) //当LTag==0时循环到中序序列第一个结点
p=p->lchild;
printf("%c",p->data); //显示结点数据,能够更改为其它对结点操作
while(p->RTag == Thread && p->rchild !=T)
{
p=p->rchild;
printf("%c",p->data);
}
p=p->rchild; //p进至其右子树根
}
return OK;
}
- 代码中,第4行,p=T->lchild;意思就是图6-10-6中的①,让p指向根结点开始遍历。
- 第5~16行,while(p!=T)其实意思就是循环直到图中的④的出现,此时意味着p指向了头结点,于是与T相等(T是指向头结点的指针),结束循环,否则一直循环下去进行遍历操作。
- 第7~8行,while(p->LTag==Link)这个循环,就是由A→B→D→H,此时H结点的LTag不是Link(就是不等于0),所以结束此循环。
- 第9行,打印H。
- 第10~14行,while(p->RTag==Thread&&p->rchild!=T),由于结点H的RTag==Thread(就是等于1),且不是指向头结点。因此打印H的后继D,之后因为D的RTag是Link,因此退出循环。
- 第15行,p=p->rchild;意味着p指向了结点D的右孩子I。 .……,就这样不断循环遍历,直到打印出HDIBJEAFCG,结束遍历操作。
从这段代码也可以看出,它等于是一个链表的扫描,所以时间复杂度为O(n)
由于它充分利用了空指针域的空间(这等于节省了空间),又保证了创建时的一次遍历就可以终生受用前驱后继的信息(这意味着节省了时间)。所以在实际问题中,如果所用的二叉树需经常遍历或查找结点时需要某种遍历序列中的前驱和后继,那么采用线索二叉链表的存储结构就是非常不错的选择。
由遍历序列确定二叉树
有一种题目为了考查你对二叉树遍历的掌握程度,是这样出题的。
已知一棵二叉树的前序遍历序列为ABCDEF,中序遍历序列为CBAEDF,请问这棵二叉树的后序遍历结果是多少?
对于这样的题目,如果真的完全理解了前中后序的原理,是不难的。 三种遍历都是从根结点开始,前序遍历是先打印再递归左和右。所以前序遍历序列为ABCDEF,第一个字母是A被打印出来,就说明A是根结点的数据。再由中序遍历序列是CBAEDF,可以知道C和B是A的左子树的结点,E、D、F是A的右子树的结点,如图6-8-21所示。

然后我们看前序中的C和B,它的顺序是ABCDEF,是先打印B后打印C,所以B应该是A的左孩子,而C就只能是B的孩子,此时是左还是右孩子还不确定。再看中序序列是 CBAEDF,C是在B的前面打印,这就说明C是B的左孩子,否则就是右孩子了,如图6-8-22所示。

再看前序中的E、D、F,它的顺序是 ABCDEF,那就意味着D是A 结点的右孩子,E和F是D的子孙,注意,它们中有一个不一定是孩子,还有可能是孙子的。再来看中序序列是CBAEDF,由于E在D的左侧,而F在右侧,所以可以确定E是D的左孩子,F是D的右孩子。因此最终得到的二叉树是图6-8-23所示。

为了避免推导中的失误,你最好在心中递归遍历,检查一下这棵树的前序和中序遍历序列是否与题目中的相同。 已经复原了二叉树,要获得它的后序遍历结果就是易如反掌,结果是CBEFDA。但其实,如果同学们足够熟练,不用画这棵二叉树,也可以得到后序的结果,因为刚才判断了A结点是根结点,那么它在后序序列中,一定是最后一个。刚才推导出C是B的左孩子,而B是A的左孩子,那就意味着后序序列的前两位一定是CB。同样的办法也可以得到EFD这样的后序顺序,最终就自然的得到CBEFDA 这样的序列,不用在草稿上画树状图了。
反过来,如果我们的题目是这样:二叉树的中序序列是 ABCDEFG,后序序列是BDCAFGE,求前序序列。 这次简单点,由后序的BDCAFGE,得到E是根结点,因此前序首字母是E。
于是根据中序序列分为两棵树ABCD和FG,由后序序列的 BDCAFGE,知道A是E的左孩子,前序序列目前分析为EA。
再由中序序列的 ABCDEFG,知道 BCD是A 结点的右子孙,再由后序序列的BDCAFGE知道C结点是A结点的右孩子,前序序列目前分析得到EAC。
中序序列 ABCDEFG,得到B是C的左孩子,D是C的右孩子,所以前序序列目前分析结果为EACBD。
由后序序列 BDCAFGE,得到G是E的右孩子,于是F就是G的孩子。如果你是在考试时做这道题目,时间就是分数、名次、学历,那么你根本不需关心F是G的左还是右孩子,前序遍历序列的最终结果就是 EACBDGF。
不过细细分析,根据中序序列 ABCDEFG,是可以得出F是G的左孩子。从这里我们也得到两个二叉树遍历的性质。
- 已知前序遍历序列和中序遍历序列,可以唯一确定一棵二叉树。
- 已知后序遍历序列和中序遍历序列,可以唯一确定一棵二叉树。
但要注意了,已知前序和后序遍历,是不能确定一棵二叉树的, 原因也很简单,比如前序序列是ABC,后序序列是CBA。我们可以确定A一定是根结点,但接下来,我们无法知道,哪个结点是左子树,哪个是右子树。这棵树可能有如图6-8-24所示的四种可能。

赫夫曼树定义与原理
从树中一个结点到另一个结点之间的分支构成两个结点之间的路径,路径上的分支数目称做路径长度 树的路径长度就是从树根到每一结点的路径长度之和。

二叉树a中,根结点到结点D的路径长度就为4,二叉树b中根结点到结点D的路径长度为2。二叉树a的树路径长度就为1+1+2+2+3+3+4+4=20。二叉树b的树路径长度就为1+2+3+3+2+1+2+2=16
如果考虑到带权的结点,结点的带权的路径长度为从该结点到树根之间的路径长度与结点上权的乘积。树的带权路径长度为树中所有叶子结点的带权路径长度之和。
假设有n个权值$w_1,w_2,..w_n$,构造一棵有n个叶子结点的二叉树,每个叶子结点带权$w_k$,每个叶子的路径长度为$l_k$。则其中带权路径长度WPL最小的二叉树称做赫夫曼树(最优二叉树)。
$二叉树a的WPL=5×1+15×2+40×3+30×4+10×4=315$ $二叉树b的WPL=5×3+15×3+40×2+30×2+10×2=220$

赫夫曼编码

线性代数-向量(三)
继续搞线代!向量这一张很多定理要去记~
恋词U12
- respectable adj.正派的;体面的;受人尊敬的;好的;令人满意的
- respective adj.各自的;分别的;单独的
- esteem v.n 尊重;敬重
- infrastructure n.基础结构;基础措施
- restructuring n.改组;重新组织;调整
- instruct v.讲;讲授;担任教学工作
- entrepreneur n.企业家;承包者;创业者
- dazzle v.使赞叹不已;使目眩 n.耀眼的光
- stunning adj.令人惊奇的;令人震惊的
- subsequent adj.随后的;后来的
- be content to do sth 愿意做某事
- contention n.争吵;争论
- emerge v.出现;暴露;显露
- merge v.使合并;使融入;融入
- immersive adj.沉浸式的
- interim n.间歇;过渡期间;中期 adj.暂时的;临时的;过渡的
- interfere v.干涉;干预;介入;妨碍
- trial n.审判;试验;比赛;选拔赛
- racial adj.人种的;种族的;
- steward n.乘务员;管家
- ward n.病房;行政区
- ward off 防止;避免
- wardrobe n.衣橱
- bore v.钻孔;挖通道;使厌烦;盯着看 n.令人讨厌的人
- deter v.阻止;使不敢
- depredation n.掠夺;损害;破坏
- elevate v.举起;提高;提升
- alleviate v.减轻;缓解;缓和
待办