Table of Contents
回顾
复习恋词U1,U2,U3,U4,U5
- reserved adj.矜持的;预计的
- gaze v.凝视
- conform v.适应;适从;遵守;服从
- confirm v.证实;批准
- infirm adj.体弱的
- toll v.向..征收捐税
- entrenched adj.根深蒂固的
- endorse v.赞同;支持;宣传;在背面签名
数据结构-取最值问题-线性表(七)
顺序表取最值问题
无论是找最大还是最小值,至少需要把整个表扫描一遍,才能知道哪一个值是最小还是最大。
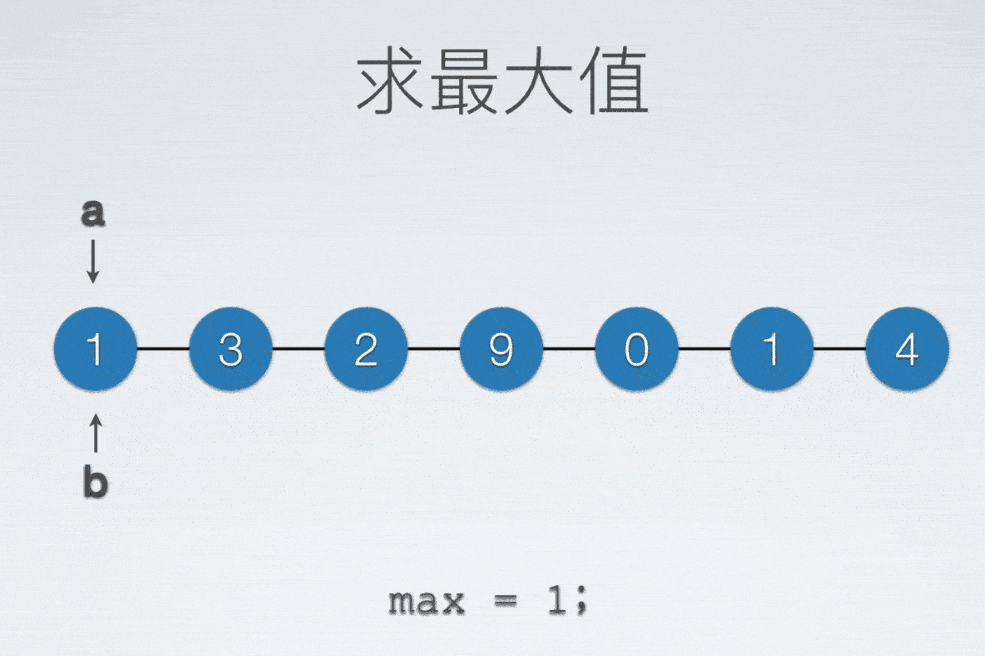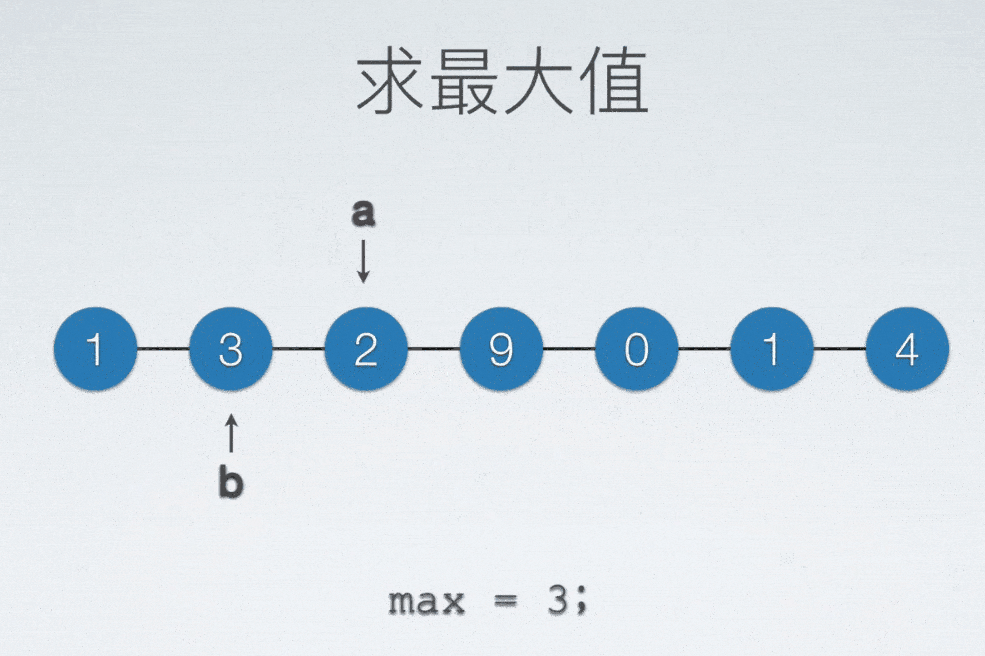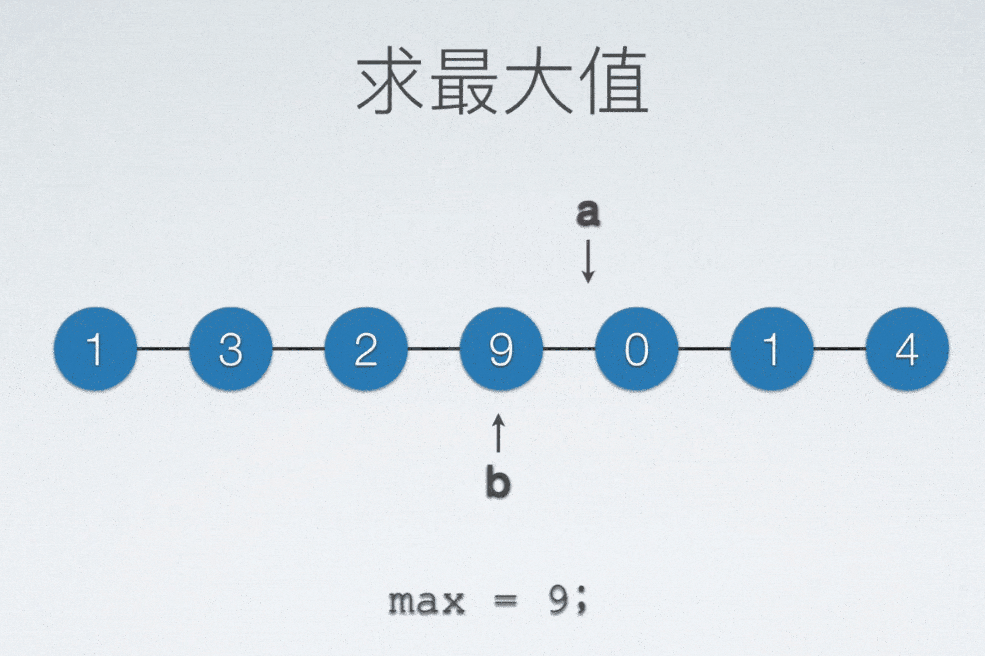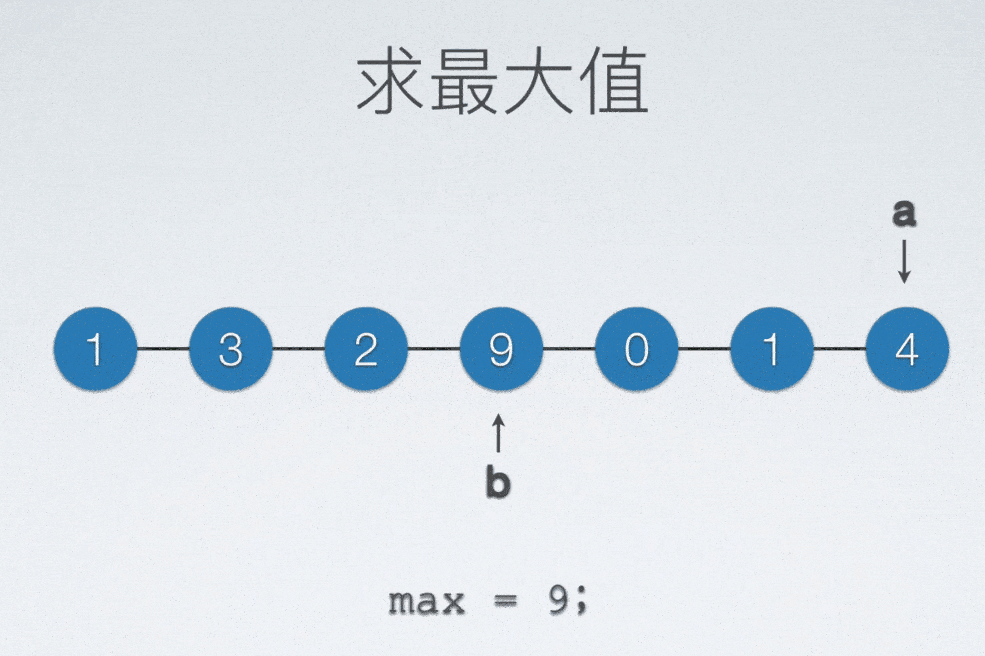
顺序表找最大值
int max = a[0]; //存最大值的变量
int maxIdx = 0; //“标记”
for(int i = 0; i < n; ++i)
{
if(max < a[i]) //当新扫描元素比现在这个最大值更大的话
{
max = a[i]; //把最大值更新为新发现的这个元素
maxIdx = i; //同时把标记更新为新发现的这个元素的数值下标
}
}
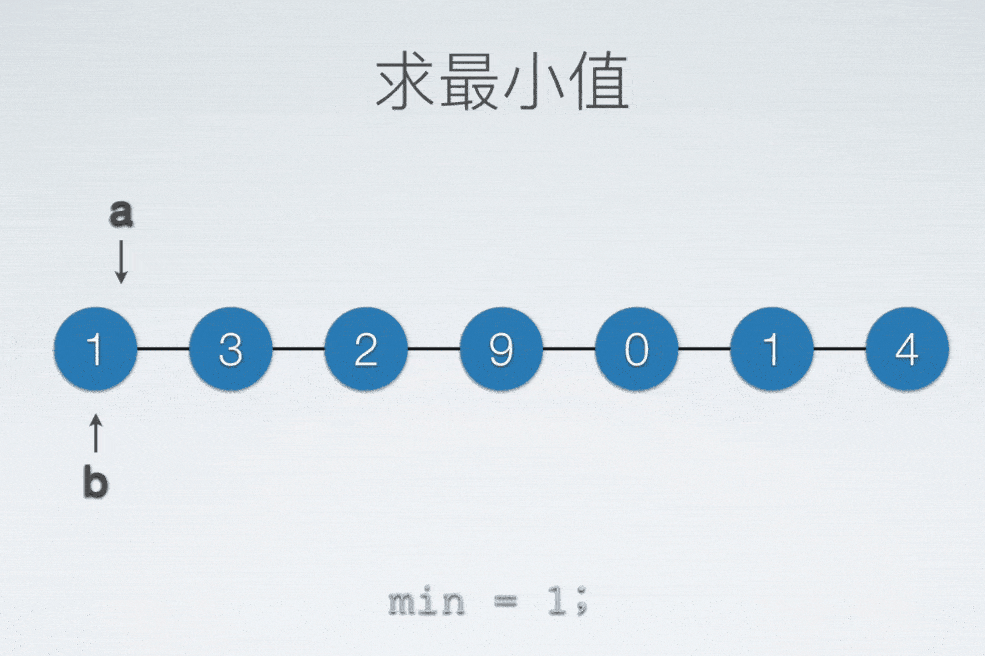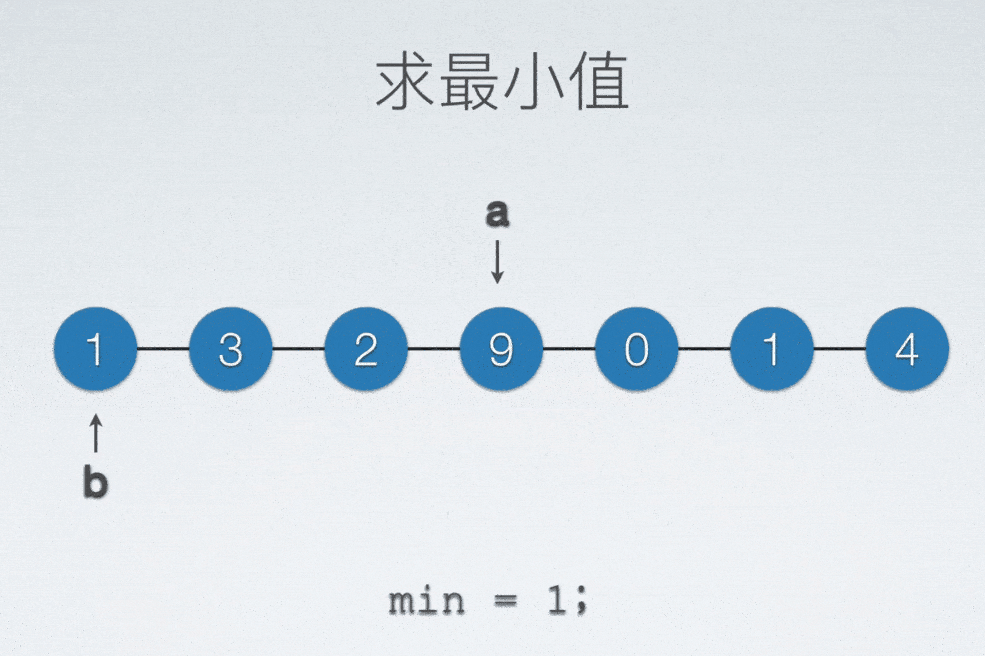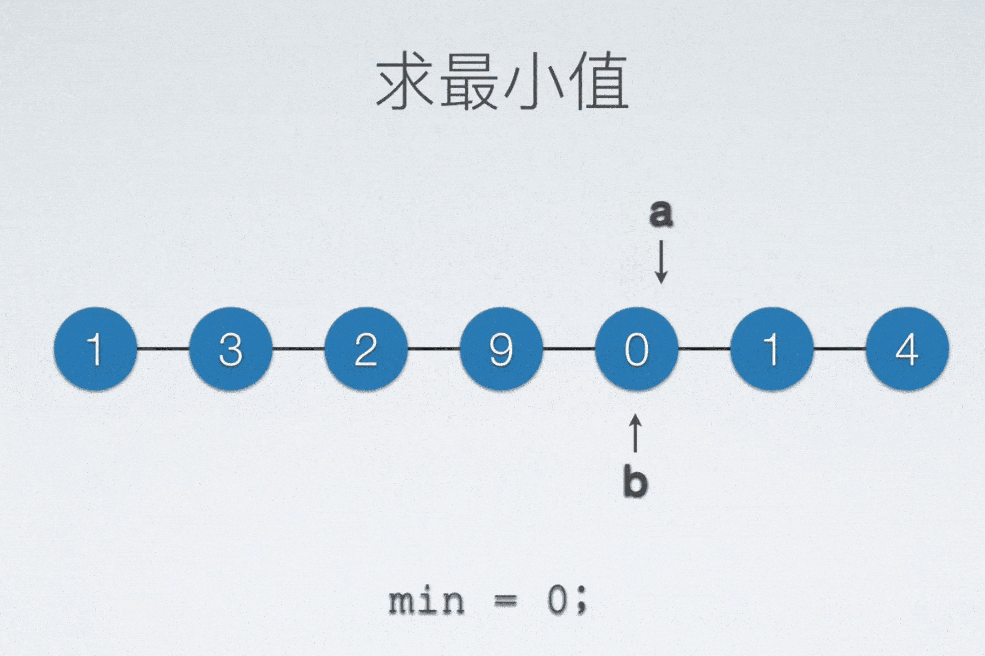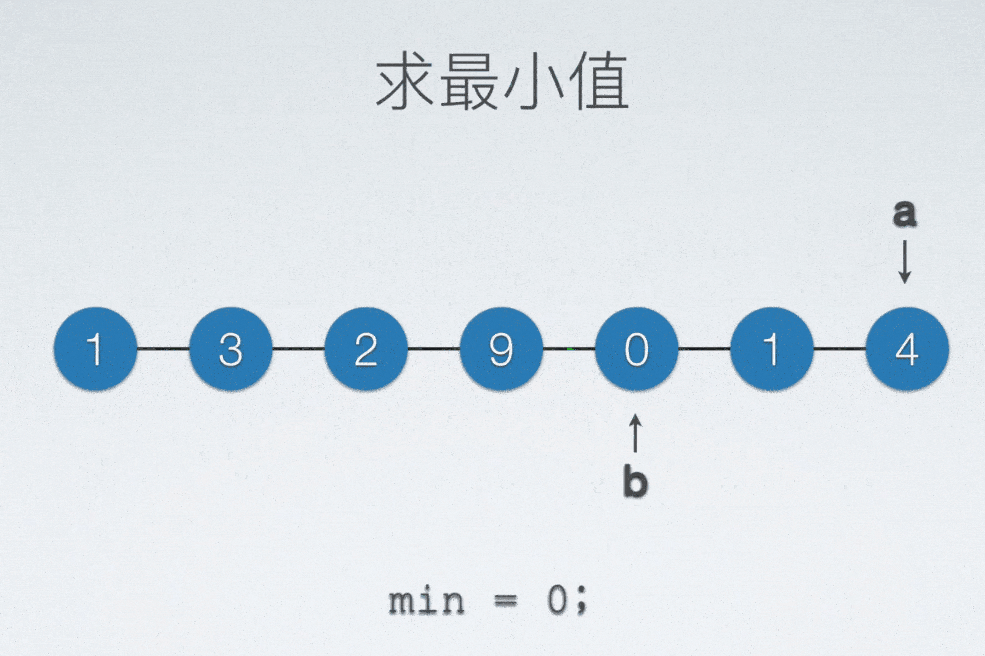
顺序表找最小值
int min = a[0];
int minIdx = 0;
for(int i = 0; i < n; ++i)
{
if(min > a[i])
{
min = a[i];
minIdx = i;
}
}
单链表取最值问题
道理一样,一个循环扫描整个链表即可。顺序表中的标记是一个整型变量,因为数组下标是整型的,那链表的标记找一个指针即可。
单链表找最大值
LNode *p, *q;
int max = head->next->data;
q = p = head->next;
while(p != NULL)
{
if(max < p->data)
{
max = p->data;
q = p;
}
p = p->next;
}
单链表找最小值
LNode *p, *q;
int min = head->next->data;
q = p = head->next;
while(p != NULL)
{
if(min > p->data)
{
min = p->data;
q = p;
}
p = p->next;
}
例题
一双链表非空,由head指针指出,结点结构为{llink,data,rlink},请设计一个将结点数据data值最大的那个结点(最大值结点只有一个)移动到链表最前边的算法,要求不能申请新结点。
分析:按照之前的方法扫描一遍双链表,找出
data域最大的那个结点,取下它移动道链表最前面即可。
void maxFirst(DLNode *head)
{
DLNode *p = head->rlink, *q = p;
int max = p->data;
//找最值
while(p != NULL)
{
if(max < p->data)
{
max = p->data;
q = p;
}
p = p->rlink;
}//虽然是双链表,但找最值得代码与单链表基本相同,因为双链表就相当于两条单链表,走其中的一条就可以把链表遍历一遍。
//“删除”(没有释放结点空间)
DLNode *l = q->llink, *r = q->rlink;
l->rlink = r;
if(r != NULL)
r->llink = l;
//插入
q->llink = head;
q->rlink = head->rlink;
head->rlink = q;
q->rlink->llink = q;
}
真题
假定采用带头结点的单链表保存单词,当两个单词有相同的后缀时,即可共享相同的后缀存储空间,比如:"loading"和"being"的存储映像如下图所示:

设str1和str2分别指向两个单词所在单链表的头结点,链表结点结构为{data,next},请设计一个时间是尽可能高效的算法,找出由str1和str2所指向两个链表共同后缀的起始位置(如图中国字符i所在结点的位置p。
- 给出算法的基本设计思想
- 根据设计思想,采用C或C++或JAVA语言描述算法,关键之处给出注释。
- 说明你所设计算法的时间复杂度。
分析:即要找到
i的位置。从任何一个链表开始遍历的话,都不知道啥时候扫描到共享结点,但是当定位到这两个结点的时候,以这种状态为起始状态,开始同步地扫描这两个链表,定会发生在其他共享结点相遇。

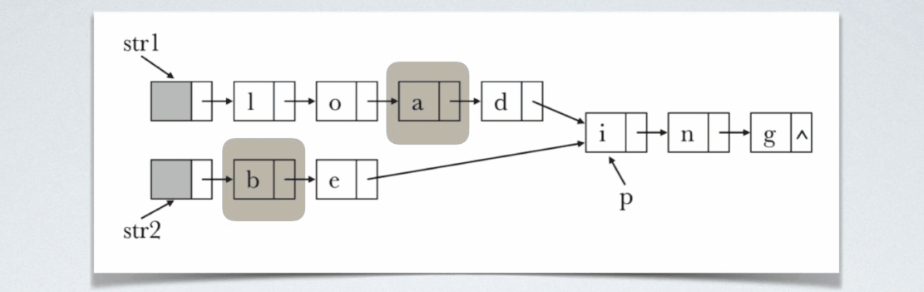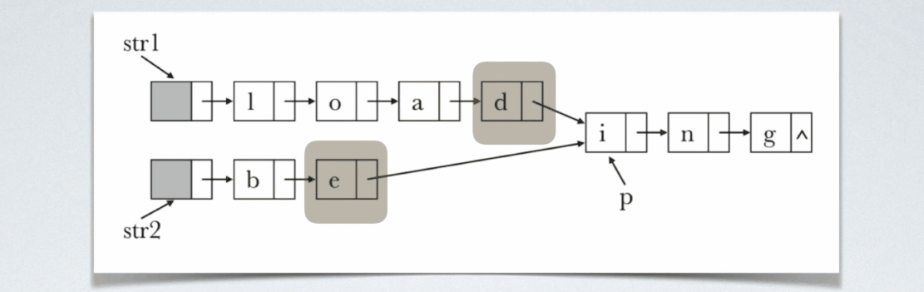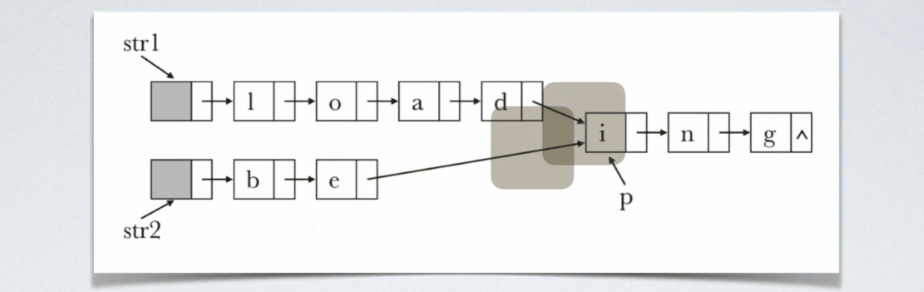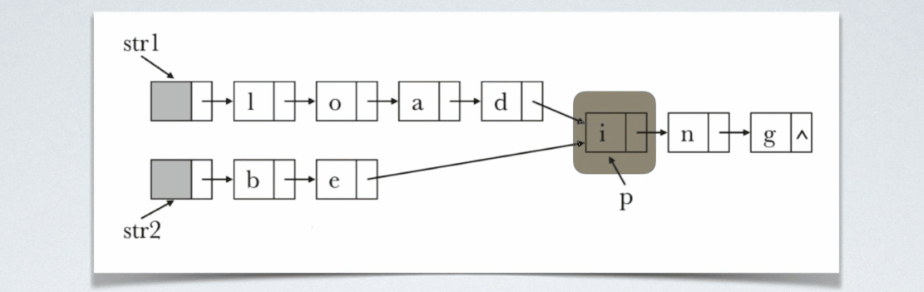
即关键在于一开始的定位。,即如何在两个链表中定位出这么两个结点,他们到共享结点的距离是相等的。可以这么处理:先各自数自己链表长度,然后用较长链表长度减去较短链表长度,得到一个差值。然后用一个指针从指针的的那个链表的表头开始走这个差值的距离,另一个指针指向较短的那个链表的第一个结点,这样呢就实现了定位,然后两指针同步走,相遇的时候即找到共享结点的时候。
答案

LNode *findFirstCommon(LNode *str1, LNode *str2)
{
int len1 = 0, len2 = 0;
LNode *p = str1->next, *q = str2->next;
while(p != NULL)
{
len1++;
p = p->next;
}
while(q != NULL)
{
len2++;
q = q->next;
}
for(p = str1->next;len1 > len2; len--)
p = p->next;
for(q = str2->next;len1 < len2;len2--)
q = q->next;
while(p != NULL && p != q)
{
p = p->next;
q = q->next;
}
return p;
}